
我是如何在資料庫處理 1.2 億 筆資料並榨出 900 倍查詢效能的?
前言:菜鳥工程師的大數據初體驗 🚀
就在我正式踏入職場,成為一名軟體工程師大約半年後,一個很有趣的題目擺在了我的面前:我需要處理台灣每日產生的大量交通數據,並將其轉化為一個 Agent 應用,讓即使是不具程式背景的交通管理人員或一般民眾,也能透過自然語言輕鬆地查詢與分析這些資料。 這不僅僅是建立一套 ETL 流程那麼簡單,更是對我資料庫知識深度與效能調校的一個考驗。
這篇文章,我想分享的便是我在這趟旅程中的所學所感,從最初的茫然,到一步步摸索、試錯,最終成功將 1.2 億筆交通相關的時序資料高效導入 Supabase,並透過資料表分區 (Partitioning) 與索引 (Indexing) 將查詢效能提升 934 倍的完整實戰記錄。希望能為同樣在資料處理道路上探索的你,提供一些借鑒與啟發。
最初的構想與碰壁:為何資料庫 Client API 不是大量導入的好選擇?
萬事起頭難,尤其是在面對如此龐大的資料量時。我最初的設想,是利用 Supabase(一種包含很多擴充的PostgreSQL) 提供的預設 API,透過 insert() 方法將處理好的 CSV 資料逐批寫入。畢竟,對於習慣了 ORM 或客戶端庫操作的我來說,這似乎是最直觀的方式。
然而,理想很豐滿,現實卻很骨感。當我開始嘗試用這種方式導入哪怕只是一小部分的資料時,就發現了幾個嚴重的問題:
- 驚人的耗時:每一條
insert()操作都是一次獨立的網絡請求和資料庫事務。對於上億筆資料,這意味著天文數字般的請求次數,導入過程將會曠日廢時。 - 資源消耗巨大:大量的併發寫入請求會給 Supabase 實例帶來巨大的負載壓力。
- 缺乏效率與彈性:對於大量的資料載入,API 呼叫的開銷遠大於直接的資料庫底層操作,而且還需要擔心是否會有因網路中斷而造成失敗。
很快我便意識到,API 更適合日常的 CRUD 操作,而非處理這種規模的批量資料導入, 我需要尋找更有效的方法。除了資料導入的效能問題外,這工作棘手的還有重複值的問題,在大型資料直接去重複會是極大的硬體開銷。
所以我是怎麼解決這個問題的?
直接發在Thread上求救。
沒錯 就這麼簡單! 畢竟我可是專業的Threader XD ,萬事問Thread其實就能很多意想不到的解答出現。沒想到演算法也眷顧了我,Thread上所有的資料庫專家都來幫我

經過各前輩的建議跟我自己的嘗試,我最終採用了下面這套流程。可以分為以下幾個階段:資料前處理 -> 使用 COPY 指令導入資料到暫存表中 -> 資料表分區 ->分區內去重複 -> 建立索引。
---
config:
look: handDrawn
layout: dagre
---
flowchart TD
A["資料前處理 CSV"] --> B["遷移檔案至伺服器"]
B --> C["使用 psql COPY 指令導入臨時表"]
C --> D["資料分區"]
D --> E["建立索引"]
style A fill:#E1BEE7
style B fill:#BBDEFB
style C stroke-width:2px,fill:#FFF9C4
style D stroke-width:2px,fill:#FFE0B2
style E fill:pink,stroke:#333,stroke-width:2px
為什麼是這樣的順序呢? 關鍵在於效率。如果在導入資料的同時就處理索引,每一筆資料的寫入都會伴隨著索引的更新開銷,這會大大拖慢整體導入速度。因此,我們先將所有原始資料快速載入,完成分區,最後再針對已就緒的資料結構統一建立索引,這樣可以最大化每個階段的處理效率。
接下來,我將一步步拆解這個過程。
第 1 步:資料前處理與分割
原始數據是一團亂 :(
這次我面對的是一個單日就高達 1.22 億筆紀錄、約 8 GB 的檔案 (甚至沒副檔名)。為了讓後續處理更順暢,前處理是必不可少的一環。
首先為了讓你們容易帶入,這是資料的欄位介紹
| 欄位名稱 | 資料型態 | 說明 |
|---|---|---|
| road_id | TEXT | 道路或路段的唯一識別碼(如「HWY1-SEG12」) |
| timestamp | TIMESTAMP | 事件記錄時間(如「2025-02-28 12:34:56」) |
| direction | INTEGER | 行駛方向(例如 1=北向,2=南向) |
| speed | INTEGER | 車輛速度(km/h,例如 60) |
| ... | ... | ... |
我的做法:
- 使用
Pandas分Chunk讀取 (每塊 500,000 筆),避免一次性載入整個巨大檔案導致記憶體爆炸。 - 篩選必要欄位:例如
road_id(道路的ID)、timestamp(紀錄時間)、direction(道路方向)、speed(車速) 等。 - 進行資料清洗:移除
NULL值記錄,並將時間戳欄位格式化為標準的%Y-%m-%d %H:%M:%STimeStamp格式。 - 初步去重複:在每個Chunk內部,基於一組唯一識別欄位 (例如
road_id、timestamp、direction) 的組合進行去重複,保留Speed最大的記錄。 - 輸出Chunk csv:最終生成了 247 個 CSV 檔案 (例如
chunk_001.csv到chunk_247.csv),儲存在./processed_data/split_csv/目錄下。
第 2 步:資料遷移至伺服器本地 – 減少網路瓶頸
資料準備好了,下一步是將它們送達資料庫所在伺服器。 與其透過網路連線逐批寫入資料(這會受到頻寬限制、網路延遲甚至斷線的困擾),一個更穩健且有效率的做法是:先將所有處理好的CSV資料完整遷移到資料庫所在的伺服器環境中。
- 目標:將本機處理完成的 247 個 CSV 檔案安全、完整地傳輸到運行資料庫服務的伺服器本地儲存上。
- 我的做法:
- 使用如
scp、rsync或其他可靠的檔案傳輸工具,將所有分割後的 CSV 檔案上傳至伺服器指定的目錄,例如/data/pending_import/。 - 仔細驗證:確保檔案數量 (247 個) 和總體大小與本地一致,並且伺服器上有足夠的磁碟空間。
- 使用如
- 這麼做的好處?
- 避免網路不穩定:一旦檔案傳輸完成,後續的導入操作就在伺服器內部進行,不再受外部網路波動影響。至少減少了一個可能的出錯環節
- 硬碟寫入肯定比較快:伺服器硬碟的讀寫速度通常遠高於網路傳輸。
- 時間成本:在 100 Mbps 的網路環境下,傳輸過程耗時約 1-2 小時。雖然這一步本身需要時間,但它為後續更快速、更可靠的導入節省了大量潛在的麻煩。
- 成果:所有 CSV 檔案成功「登陸」伺服器,準備好被資料庫「消化」。
第 3 步:善用原生 COPY 指令
- 建立臨時表:首先,在 PostgreSQL 資料庫中建立一個結構與 CSV 檔案對應的臨時表。
CREATE TABLE traffic_event_temp (
road_id TEXT,
timestamp TIMESTAMP,
direction INTEGER,
speed INTEGER
-- 根據你的 CSV 實際欄位定義更多欄位
);
- 接著我選擇 PostgreSQL 的原生指令
COPY來載入全部資料
廣泛應用於資料遷移、備份與 ETL 流程。相較於逐行 INSERT,COPY 繞過 SQL 解析,直接處理資料流,效能極高,支援處理 CSV、文字或二進位檔案。
基本用法
COPY table_name [(column_name, ...)]
FROM 'file_path' [WITH (option, ...)];
COPY table_name [(column_name, ...)]
TO 'file_path' [WITH (option, ...)];範例
-- 匯入 CSV 到資料表
COPY users (id, name, email)
FROM '/data/users.csv'
DELIMITER ',' CSV HEADER;
-- 匯出資料表到 CSV
COPY users TO '/data/output.csv'
DELIMITER ',' CSV HEADER;
為了最大化導入效率,我編寫了一個簡單的腳本來平行執行 COPY 命令
import os
import subprocess
from concurrent.futures import ProcessPoolExecutor
from pathlib import Path
import logging
# 設定日誌
logging.basicConfig(
filename='import_errors.log',
level=logging.ERROR,
format='%(asctime)s - %(levelname)s - %(message)s'
)
# 資料庫連線資訊
DB_HOST = "localhost"
DB_USER = "user"
DB_NAME = "mydb"
def import_single_csv(csv_file):
try:
# 構建 psql COPY 指令
psql_cmd = (
f"psql -h {DB_HOST} -U {DB_USER} -d {DB_NAME} -c "
f"\"COPY traffic_event_temp (road_id, timestamp, direction, speed) "
f"FROM '{csv_file}' DELIMITER ',' CSV HEADER\""
)
subprocess.run(psql_cmd, shell=True, check=True)
print(f"成功導入 {csv_file}")
except subprocess.CalledProcessError as e:
logging.error(f"導入 {csv_file} 失敗: {e}")
print(f"導入 {csv_file} 失敗,詳情見日誌")
# CSV 檔案目錄(伺服器本地路徑)
csv_directory = "/data/pending_import/"
csv_files = list(Path(csv_directory).glob("*.csv"))
# 使用平行處理
with ProcessPoolExecutor(max_workers=4) as executor:
executor.map(import_single_csv, csv_files)
這裡的關鍵是利用 COPY 指令直接從伺服器本地檔案系統讀取資料並寫入資料庫,繞過了許多 SQL 層的開銷。使用如 concurrent.futures (Python) 或 xargs -P (Shell) 等工具可以輕鬆實現並行處理。
第 4 步:Table Partition 減少查詢時間
資料表分區(Partitioning)是將大型資料表分割成多個較小的子表(分區),以提升查詢效率和管理性。每個分區獨立儲存,但邏輯上仍屬於同一父表,適用於社群網站、金融業等高流量場景。分區可按範圍(如時間)、列表(如類別)或雜湊分割資料,結合資料複製(Replication),將分區分散到不同伺服器節點,有著下面好處:
- 提高資料查詢效率:Partition縮小查詢範圍,減少查詢時間。
- 容錯性:複製將資料備份到多節點,某節點故障不影響整體服務。
- 流量分散:分區和複製分擔讀寫壓力,避免單一伺服器或磁碟超載。
結合 Partition 與Replication 可以將負載分散到不同節點中,也可以提高Server的故障容錯,其中一個節點停機也不會影響整體系統,推薦可以去看Designing Data-Intensive Application(DDIA) 這本書,裡面對於這方面的知識非常淺顯易懂。
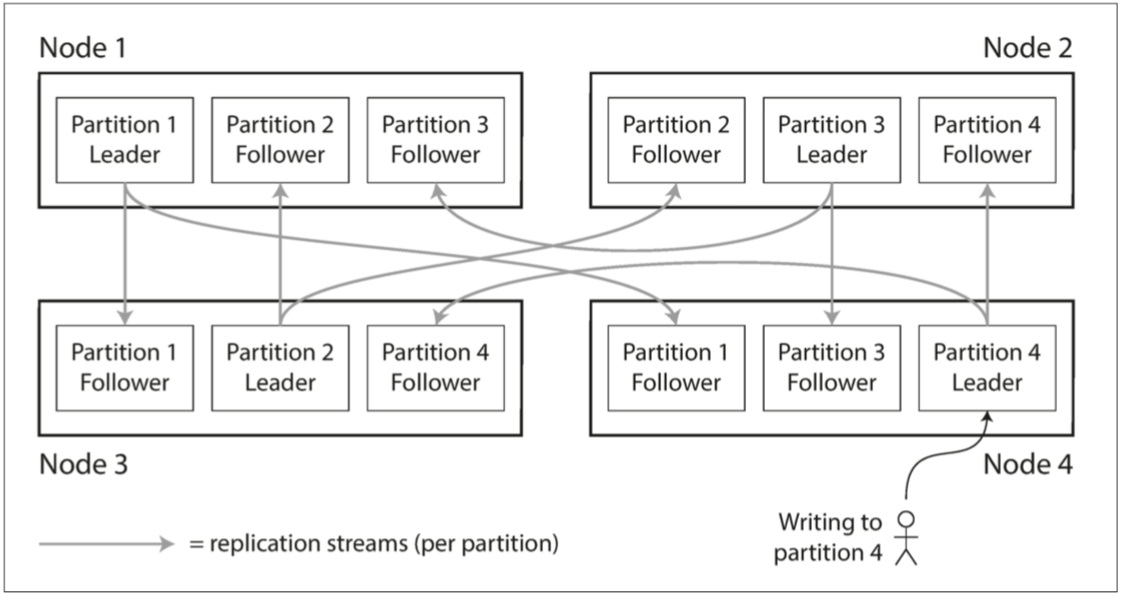
但對於我的案例來說,我沒有要擔心那麼多問題XD 我這邊只會用到Partition,目的是減少資料的查詢時間。
所以先創造了一個Table,準備來把資料從Temp表轉移到正式資料表fact_traffic_events 中
CREATE TABLE fact_traffic_events (
road_id TEXT,
timestamp TIMESTAMP,
direction INTEGER,
speed INTEGER
) PARTITION BY RANGE (timestamp);這邊可以看到的是我先不設立主鍵,主要原因是我資料太多,在資料導入後期維護索引會是寫入的主要效能瓶頸,因此等資料全部導入後再去建立索引跟主鍵,當然如果你的資料是包含外鍵的話,也建議等你導入完資料再建立
將臨時表 traffic_event_temp 中的資料,按照 timestamp (事件時間) 欄位,以小時為單位,分散到 24 個獨立的分區子表中。這些子表都隸屬於一個名為 fact_traffic_events 的父表。
我使用一個 DO 區塊和迴圈,為特定日期 (本次示範為 2025-02-28的資料) 的每一小時都創建一個分區子表,並使其成為父表的一個分區。
-- 動態建立分區子表
DO $$
DECLARE
target_date TEXT := '2025-02-28'; -- 示範抓取2/28資料
hour_padded TEXT;
start_time TEXT;
end_time TEXT;
partition_name TEXT;
BEGIN
FOR hour_val IN 0..23 LOOP
hour_padded := lpad(hour_val::text, 2, '0');
start_time := target_date || ' ' || hour_padded || ':00:00';
end_time := target_date || ' ' || lpad((hour_val + 1)::text, 2, '0') || ':00:00';
partition_name := 'traffic_events_' || replace(target_date, '-', '') || '_' || hour_padded;
EXECUTE format(
'CREATE TABLE %I PARTITION OF fact_traffic_events
FOR VALUES FROM (%L) TO (%L);
CREATE INDEX ON %I (timestamp);',
partition_name, start_time, end_time, partition_name
);
END LOOP;
END $$;
-- 插入資料
INSERT INTO fact_traffic_events
SELECT * FROM traffic_event_temp
WHERE timestamp IS NOT NULL;第 5 步:分區內去重複與建立主鍵索引
數據分區後,還需要在每個分區內部進行更精細的優化。
- 在每個小時的分區子表內部,進行去重複。這次的去重複邏輯是:對於相同的唯一識別鍵組合 (例如
road_id、timestamp、direction),只保留speed(測量值) 最大的那條記錄。 - 為每個去重後的子分區表,在選定的主鍵欄位 (例如
road_id、timestamp、direction) 上建立Pkey,來確保未來若資料查詢時可以透過Pkey來索引,Pkey的強制唯一性也不會造成重複資料寫入
-- 第 5 步:分區內去重與建立主鍵索引
DO $$
DECLARE
hour_padded TEXT;
partition_name TEXT;
pkey_name TEXT;
BEGIN
SET maintenance_work_mem = '256MB';
FOR hour_val IN 0..23 LOOP
hour_padded := lpad(hour_val::text, 2, '0');
partition_name := 'traffic_events_20250228_' || hour_padded;
pkey_name := partition_name || '_pkey';
EXECUTE format(
-- 去重:保留 MAX(speed) 的記錄
'DELETE FROM %I WHERE ctid NOT IN (
SELECT ctid FROM (
SELECT ctid, ROW_NUMBER() OVER (
PARTITION BY road_id, timestamp, direction
ORDER BY speed DESC
) AS rn
FROM %I
) t WHERE rn = 1
);
-- 建立唯一主鍵索引
CREATE UNIQUE INDEX CONCURRENTLY %I
ON %I USING btree (road_id, timestamp, direction);
ALTER TABLE %I
ADD CONSTRAINT %I PRIMARY KEY USING INDEX %I;',
partition_name, partition_name,
pkey_name, partition_name, partition_name, pkey_name, pkey_name
);
END LOOP;
RESET maintenance_work_mem;
END $$;第 6 步: 效能比較
最後我對比了在未分區、無索引的臨時表 (traffic_event_temp) 和經過分區、有索引的父表 ( fact_traffic_events) 上執行查詢,前者沒有經過任何的優化(分區與建立索引),而後者則是有進行分區跟索引。
為了凸顯沒有任何優化手段的資料庫會帶來的效能災難,我在這邊進行一個不公平的比較 (沒錯 你被標題詐欺了XD),有優化的表的查詢指令有指定時間範圍,所以DB就可以針對指定時間範圍內的分區來查詢,而不用掃描整個表,此外索引也會極度影響DB性能。
測試查詢:
-- 查詢臨時表 (無分區/無索引)
EXPLAIN ANALYZE SELECT * FROM traffic_event_temp
WHERE road_id = 'EXAMPLE_ROAD_ID_XYZ' -- 替換為一個實際存在的 ID
ORDER BY timestamp DESC;
-- 查詢分區表 (有分區/有索引)
EXPLAIN ANALYZE SELECT * FROM fact_traffic_events
WHERE road_id = 'EXAMPLE_ROAD_ID_XYZ' -- 替換為一個實際存在的 ID
AND timestamp >= '2025-02-28 07:00:00' -- 添加時間範圍以利用分區剪枝
AND timestamp <= '2025-02-28 11:00:00'
ORDER BY timestamp DESC;
- 比較結果:
- 臨時表 (完全無優化):
- 耗時:4479.774 ms (約 4.48 秒)
- 實際行為:全表掃描1.2 億筆記錄,然後排序。
- 分區表 (已優化):
- 耗時:4.795 ms (約 0.005 秒)
- 實際行為:對相關的幾個分區進行掃描 ,然後排序。
- 臨時表 (完全無優化):
- 效能提升高達 934 倍! (但實際應該不會有工程師那麼蠢去建立那樣的表
為了更清晰地展示整個資料處理流程,我用 Mermaid 繪製了如下的流程圖:
---
config:
look: handDrawn
layout: dagre
---
flowchart TD
subgraph A[資料準備階段]
direction LR
A1[原始資料] --> A2{Pandas Chunk讀取};
A2 --> A3[篩選欄位、格式化、Chunk內去重複];
A3 --> A4[輸出Chunk File];
end
subgraph B[數據傳輸與導入至臨時表]
direction LR
B1[傳輸Chunk CSV 至伺服器本地] --> B2{建立臨時表 traffic_event_temp};
B2 --> B3[平行執行 psql COPY 指令];
B3 --> B4[資料成功導入臨時表];
end
subgraph C[資料庫優化:分區與索引]
direction LR
C1[建立分區父表 fact_traffic_events] --> C2[動態創建各時段分區子表];
C2 --> C3[臨時表數據INSERT至父表自動路由];
C3 --> C4[各分區內再次去重複 例如 MAXvalue];
C4 --> C5[為每個分區建立主鍵索引];
end
subgraph D[效能驗證]
direction LR
D1[查詢優化前 臨時表: ~4.48秒] --> D2[執行相同條件查詢];
D2 --> D3[查詢優化後 分區表: ~0.005秒];
D3 --> D4[效能提升約 934 倍!];
end
A --> B;
B --> C;
C --> D;
style A fill:#E3F2FD,stroke:#333,stroke-width:2px
style B fill:#E8F5E9,stroke:#333,stroke-width:2px
style C fill:#FFF9C4,stroke:#333,stroke-width:2px
style D fill:#FFEBEE,stroke:#333,stroke-width:2px
總結
- 選擇對的方式寫入資料:面對大量數據導入,
COPY遠比應用程式層的 API 有效率,但如果只是日常CRUD,選擇簡單的方法準沒錯 - 減少容易出錯的環節:能夠少一個可能出錯的環節就能節省你的寶貴時間!先將資料遷移至資料庫伺服器內再執行導入,能避免掉網路瓶頸或是連線不穩定帶來的導入中斷。
- 善用資料表分區:它能縮小資料庫的查詢範圍,配合索引更能發揮巨大威力。
- 先載入資料,後建索引:面對大量數據的寫入,這能大幅縮短整體處理時間。
提問
問題:
為什麼不直接在最初用 Pandas 處理那 247 個 CSV 檔案時,就徹底完成去重複呢?那時候資料已經被切分成小塊了,針對每一塊去重複,不是更早解決問題嗎?
答:
理想情況下,如果能在 Pandas 處理 CSV 的階段就將所有重複資料清除乾淨,確實會讓後續流程更單純。然而,在這次的實戰中,我遇到了幾個的挑戰:
- 重複資料可能跨越不同的 CSV 檔案 (Chunk): 我所處理的原始交通數據是未經排序的。這意味著,邏輯上屬於同一筆事件但因某些原因重複出現的記錄(例如,相同的
road_id、timestamp、direction),有可能一筆出現在chunk_001.csv,而另一筆重複的記錄卻出現在chunk_034.csv。如果僅在單一 CSV 檔案內部進行去重複,是無法捕捉到這種跨檔案的重複情況。 - 資源的限制: 要在 Pandas 中實現「全局去重複」(即考慮所有 1.2 億筆資料來找出所有重複),就需要將所有資料或至少是足以判斷重複的關鍵欄位載入到記憶體中進行比對和排序。對於我的個人電腦而言,可能連120萬筆都有問題
因此,我選擇的策略是:
- 初步Chunk內去重複: 在 Pandas 處理每個 CSV Chunk 時,先進行一次初步的、Chunk 內的去重複。這能減少一部分明顯的重複,並為後續處理減輕負擔。
- 分區後去重複: 在將所有資料根據
timestamp分散到各個分區子表後,我才在每個分區內部執行更嚴格的去重複邏輯(即針對相同的road_id、timestamp、direction,只保留speed最大的記錄)。
這樣做的好處是:
- 保證最終資料的唯一性: 由於我的分區鍵
timestamp是判斷重複的關鍵欄位之一,相關的重複記錄基本上會被路由到同一個小時的分區內。在分區內去重,就能有效地消除這些重複。 - 高效處理: 資料庫在分區內執行去重操作時,僅需掃描該分區的數據,而無需對整個龐大的資料集進行全局掃描或排序,這在效能上遠優於在本機用 Pandas 處理全局去重的負擔。
簡單來說,這是在資料特性(未排序、重複跨檔案)、可用資源(本機記憶體)與處理效率之間做出的一個權衡。透過先將資料載入資料庫並利用其分區特性,我能以更可控且高效的方式達成最終的資料去重複目標。
結語
這次處理億級數據的挑戰,對我而言只是一個開始。未來,我還將繼續探索如何使用 Data Orchestrater (Dagster) + dlthub 來建立一個Data Pipeline,以及使用DuckDB和Clickhouse的組合全來進行資料ETL。
真的是 好多東西可以學XD
如果你也在處理類似的大數據難題,或者對我的方法有任何疑問和建議,都非常歡迎留言交流!讓我們在數據的海洋中共同成長。
如果您覺得這篇文章對您有幫助,也歡迎將其分享給其他可能需要的朋友或同事!